


Our Blog
08 JanWarum haben Salesforce Record-Ids eine Länge von 15 und 18 Zeichen?
Vielleicht seid Ihr auch schon einmal darüber gestolpert, dass Salesforce Datensätze mal 15 Zeichen lang sind, mal 18. Und hier spreche ich vom gleichen Datensatz, beispielsweise einem Account. Direkt im Link oder in einem Export von einem Report werden 15 Zeichen ausgegeben, nutzt man hingegen den DataLoader sind es 18. Was steckt also dahinter?
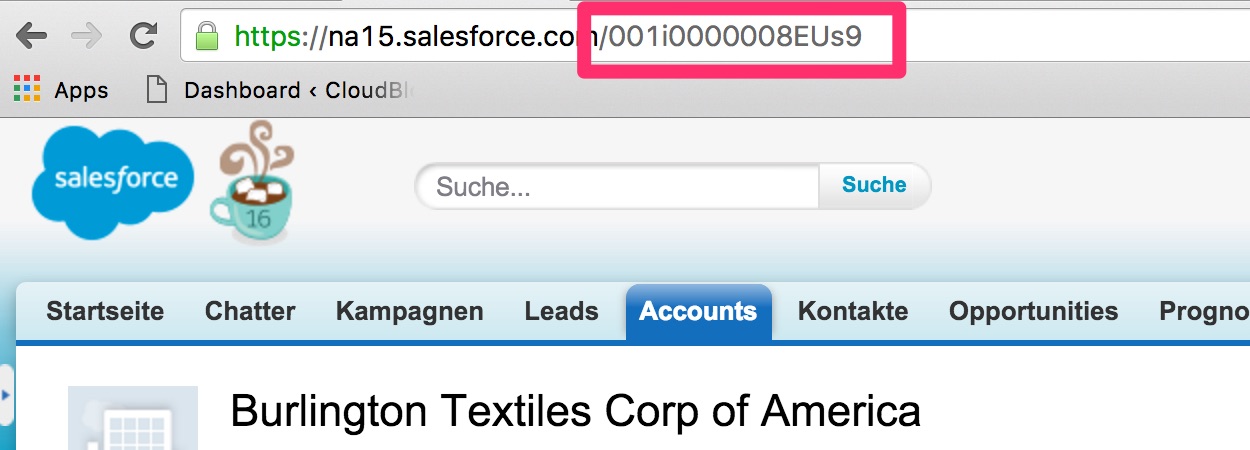
Der Grund weshalb ich diesen Post schreibe ist, dass ich Zeuge wurde wie ein neuer Admin eine Große Anzahl der vorhandenen 100.000 Account Daten unbrauchbar gemacht hatte indem ihm der Unterschied nicht klar war. Spätestens jetzt habe ich Eure Aufmerksamkeit! (Wir konnten die Daten übrigens retten, es gab ein Backup).
Was steckt also dahinter?
Die 15-stellige ID ist case sensitive, d.h. es ist ein Unterschied, ob eine ID 001i000000032b oder 001i000000032B lautet.
Das Problem entsteht in externen Programmen in denen Salesforce Daten verwendet werden. Excel beispielsweise unterscheidet nicht zwischen Groß- und Kleinbuchstaben, d.h. in einem VLOOKUP (SVERWEIS auf deutsch) sind beide Datensätze die gleichen! Und jetzt wisst Ihr auch schon, dass das sehr häßlich werden kann.
Aus diesem Grund gibt es weitere 3 Stellen, die von Salesforce am Ende hinzugefügt werden wenn Ihr die Daten exportiert. In meinem Beispiel wäre das dann beispielsweise: 001i000000032b43x und 001i000000032Bj4s. Das kann dann auch Excel nicht mehr verwechseln.
Ein gern genommener Anfängerfehler ist, Daten über einen Report zu exportieren und dann in Excel zu verarbeiten.
Das mag zwar bequem erscheinen, ist aber ein totales No-Go. Nutzt für externe Verarbeitung IMMER 18-stellige IDs, am einfachsten geht das über einen DataLoader (Original von Salesforce, Jitterbit DataLoader, dataloader.io oder andere).
Kann ich die 3 zusätzlichen Stellen auch selbst hinzufügen?
In Salesforce selbst sind die IDs 15-stellig gespeichert, das erspart Speicherplatz. Die 3 zusätzlichen Stellen werden bei Bedarf berechnet. Salesforce hat zu diesem Zweck die Formel CASESAFEID(Id) eingeführt. Falls Ihr im Netz auch über komplexe Algorithmen stolpert mit denen Ihr das berechnen könnt, so solltet Ihr wissen, dass die Funktion CASESAFEID(Id) erst in Spring’12 eingeführt wurde, vorher musste man sich mit einer sehr, sehr langen Formel helfen, die seitdem obsolet ist.
Und denkt immer daran: Wenn Ihr Daten in einem externen System verarbeitet, macht vorher ein Backup!
Wie geht Ihr mit den IDs um? Wir freuen uns über Rückmeldungen.

